What are metadata and why are they important?¶
In this chapter: metadata schema, XML and XSD, metadata optionality and possible values.
definition
Metadata are “data that provide information about other data”.
The data we wish to have information about are language data and tools/services which process them. The basic metadata elements used to describe the aforementioned are:
corpora(i.e. collections of texts or other media),lexical/conceptual resources(i.e. collections of terms),language descriptions(i.e. grammars), andtoolsorservices(i.e. software for natural language processing).
These metadata elements have multiple features and properties. For example the corpus element has several children (hierarchically dependent elements), as shown in the image, which are metadata themselves:
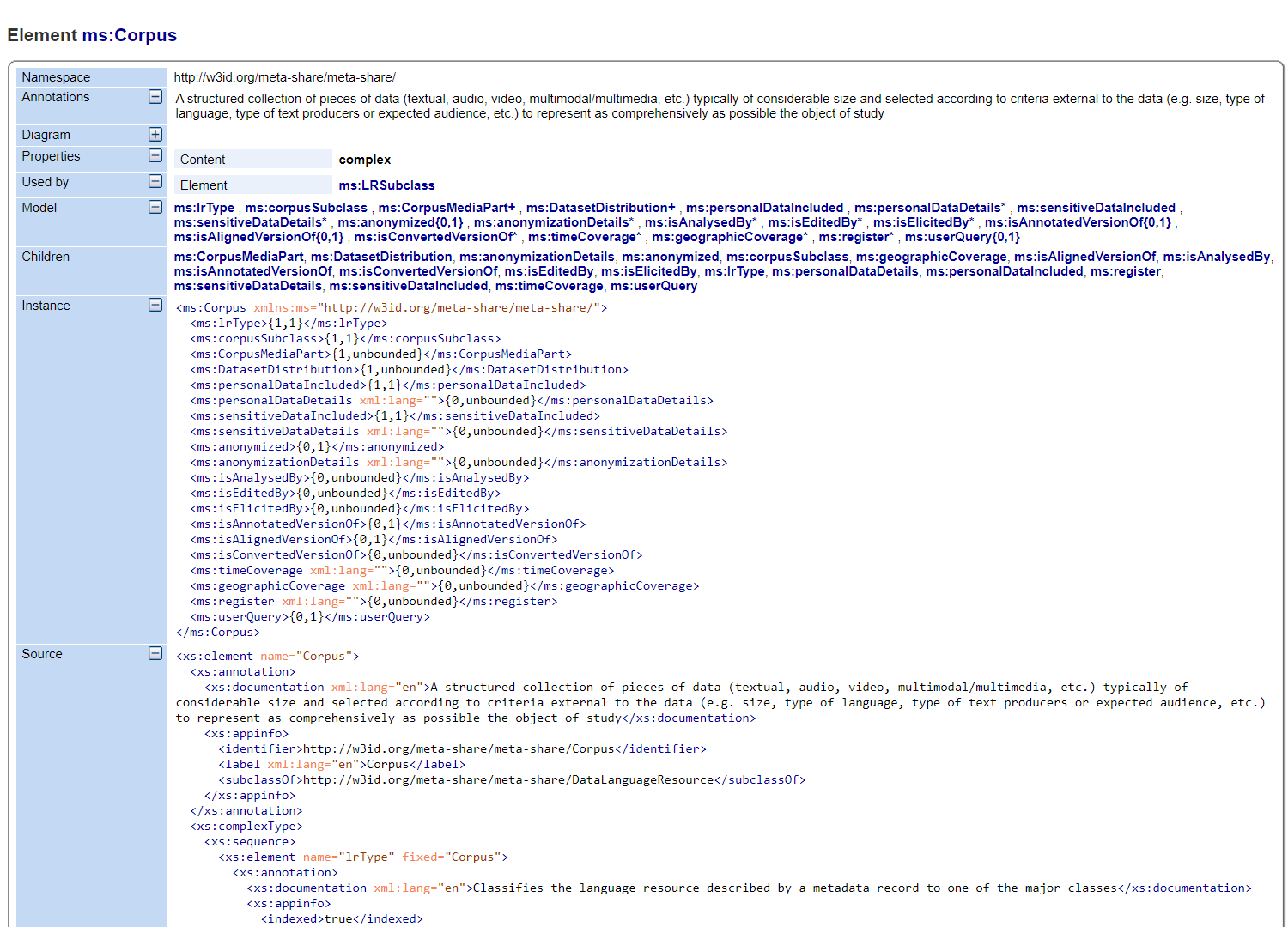
What is shown in the image above is a part of the CLARIN:EL metadata schema dedicated to the corpus element. A schema is a complicated detailed map where all elements are located, defined, described and associated with each other hierarchically. All this information is stored in a external document called XSD: XML Schema Documentation.
XML stands for eXtensible Markup Language. It is a language designed to label data by using tags <> 1. The tags represent the data structure and contain the metadata. The XSD also expresses a set of rules to which an XML document must conform in order to be considered valid (according to a specific schema).
The schema is created to help different types of users to describe, organize, retrieve and reuse resources (for more information see the Fair Principles section). As for the resources found in CLARIN:EL, the schema created provides information on questions such as the following:
What is the nature of the resources?
How were the resources created?
Why were they created?
When were they created?
Who created them?
What were the standards/tools/techniques used, if any?
What is their size (in various units)?
What was their source?
The CLARIN:EL metadata schema has also foreseen for the various media, the different languages and other useful information on all types of resources which are expressed by the respective metadata elements.
Each piece of information encoded as a metadata element is more or less necessary for the description of a resource. This is expressed by the various degrees of optionality as depicted in the following table:
If a metadata element is |
Then |
|---|---|
mandatory |
it must always be provided |
recommended |
it is still important, therefore should be provided |
mandatory upon condition |
it becomes mandatory after a certain value of another element has been filled in |
recommended upon condition |
it becomes recommended after a certain value of another element has been filled in |
optional |
“you should never say ‘this metadata isn’t useful’; be generous and provide it anyway!”2 |
Tip
See here the mandatory metadata elements for CLARIN:EL.
Each element takes a specific value. This value is the acceptable content to be enclosed between the metadata tags and it varies from alphanumeric strings to float numbers, URLs etc. These values are instantiated in some of the following examples (click on the arrow to reveal the example).
a single word:
<ms:keyword xml:lang=”en”> alignment </ms:keyword>
a phrase:
<ms:categoryLabel xml:lang=”en”> Political Science </ms:categoryLabel>
multiple phrases/paragraphs:
<ms:description xml:lang=”en”> This is a collection of the raw minutes of the Greek Parliament plenary sessions of the last 30 years (more than 1.000.000 speeches). The existing corpus has all raw data in txt format. In order to make the resource more processable, we have also split it into smaller subcorpora, with a maximum compressed folder size of 40 Mb per subcorpus. The created subcorpora are thematically organized per Greek parliamentary terms. </ms:description>
a date:
<ms:creationStartDate> 2005-10-01 </ms:creationStartDate>
a number:
<ms:amount> 100000.0 </ms:amount>
a URL:
<ms:website> http://www.ilsp.gr/ </ms:website>
an email:
<ms:email> name@athenarc.gr </ms:email>
You can see more examples here.
- 1
You can export the description of a resource in XML by visiting its view page.
- 2
FAIR Principles > F2: Data are described with rich metadata.