Specific guidelines on mandatory metadata¶
In this chapter: how to fill in the mandatory metadata.
This section provides guidance on how to fill in specific metadata which are mandatory for a corpus, a lexical/conceptual resource, a tool and a language description. Since some of the metadata elements are common for all resources, they are presented first followed by metadata which are resource type specific.
Each metadata element is briefly explained and examples are provided whenever possible. The examples cover both best practices as well as common mistakes which must be avoided (marked with an asterisk *). In addition for each metadata element there is a link to the XSD with its full representation.
1. resourceName¶
~The official name or title of the language resource/technology~
The name must reflect the content (and the type) of the resource; it must present all the necessary information for the resource but it should not be too descriptive; detailed information must be provided in the description. Do not use full phrases, punctuation marks (unless necssary) or abbreviations in the resource title. Provide the full name of the resource and use the short name (if any) in the respective metadata field.
Examples
Do: Glossary of medical terms; Old and New Testament; Ellogon annotation tool
Don’t: *This is a glossary of medical terms; *Old and New Testament!; *Ellogon ann. tool
See how the
resourceNameelement is described in detail in XSD
2. description¶
~A short presentation of the language resource/technology~
The description must contain all the important information about the resource. Don’t simply repeat (or rephrase) the resource title without adding any other information. Once read and without seeing the rest of the metadata, one should be able to understand what it is about. Define the type of the resource and provide any useful information on how, when and by whom it was created, what is its language and size and what is the purpose it serves, if any. Mention any particularities or limitations about the data or the tool that users should be aware of. The description must be a free text of minimum one paragraph. You can also make use of the functionalities (formatting, hyperlinking, bullets etc.) of the metadata editor 1 to make the description easy to read.
Examples
Do: 1) Bilingual glossary (German / Greek) made in 2019/2020 by students of DFLTI (Ionian University) under the supervision of Mr. Olaf Immanuel Seel in the framework of the department’s cooperation with the EU TermCord.
Texts corpus from the transcription of recorded children’s speech focused on narration. The corpus was collected from interviews conducted by undergraduate and postgraduate students of the Department of Mediterranean Studies of the University of the Aegean with children with whom they are related either by friendship or kinship. Files with both the questions and answers are provided, where K=girl and A=boy, as well as cleaned files containing only the children’s answers (clean).
Don’t: *Symposium Proceedings; *Bilingual lexicon on the Greek economy
See how the
descriptionelement is described in detail in XSD
3. version¶
~A particular form of a resource differing in certain respects from an earlier form~
The recommended format for a version is: major_version.minor_version.patch 2.
The infrastructure automatically assigns the 1.0.0 version to all resources. If this is not the case with your resource, write the version number in the box (e.g. 2.0.0) and then click on the version date to reveal the calendar. Select the date when this version was released and click on OK.
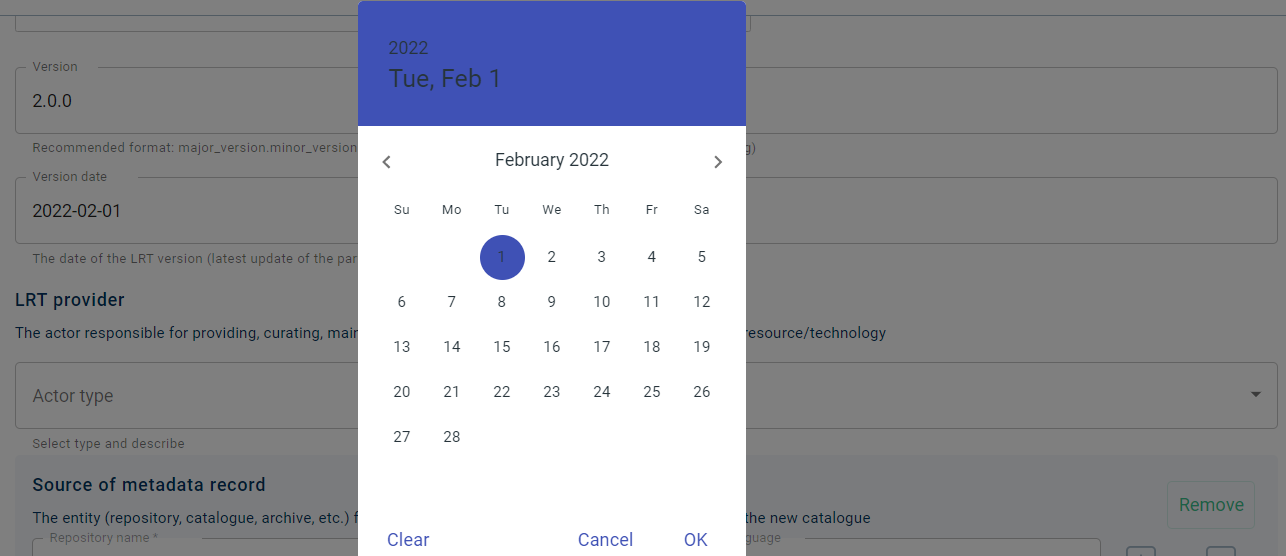
The editor also provides the possibility to automatically create a new version of an existing resource. See the guidelines on versioning before you proceed to do so.
See how the
versionelement is described in detail in XSD
4. keyword¶
~A word or phrase characteristic of the language resource/technology that can be used at search~
Keywords are words or small phrases used to search for a resource. The more keywords used, the merrier for the resource retrieval. However, the keywords must highlight resource aspects not already covered by mandatory metadata. If, for example, you describe a monolingual annotated corpus created to enhance the learning process of non native speakers, your keywords must not be exclusively or primarily the following: “corpus”, “annotated” or “monolingual”; these are the values of the resourceType, corpusSubclass and linguality metadata elements respectively which are also searched and retrieved. Instead use as keywords the phrases “non native speaker” and “learning process” which emphasize the resource intended use; in addition you can add “corpus”, “annotated” and “monolingual”.
Examples
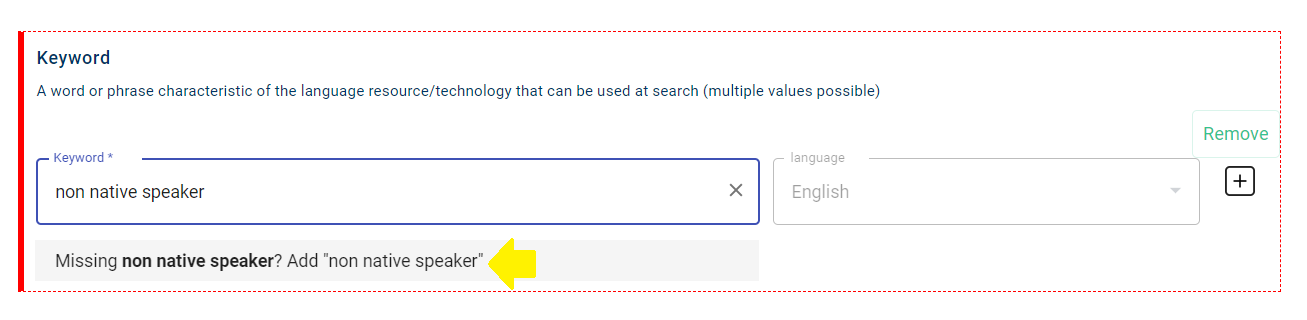
Do: non native speaker; learning process (corpus; annotated; monolingual)
After you have typed in the keyword you want, click on the prompt that appears under the box: Add “non native speaker”. Only then the value will be saved. If you omit this step, the keyword will not be appear when you revisit this editor section.
See how the
keywordelement is described in detail in XSD
5. additionalInformation¶
~A URL (landing page) or email (e.g., support email) where the user can find or ask for more information~
This metadata element is either a web page with additional information on the language resource/technology (e.g., its contents, link to the access location, etc.) or the email of person responsible to provide information. Make sure to enter a valid email or URL.
See how the
additionalInformationelement is described in detail in XSD
6. distribution related metadata¶
~The form (or forms) in which a resource is available~
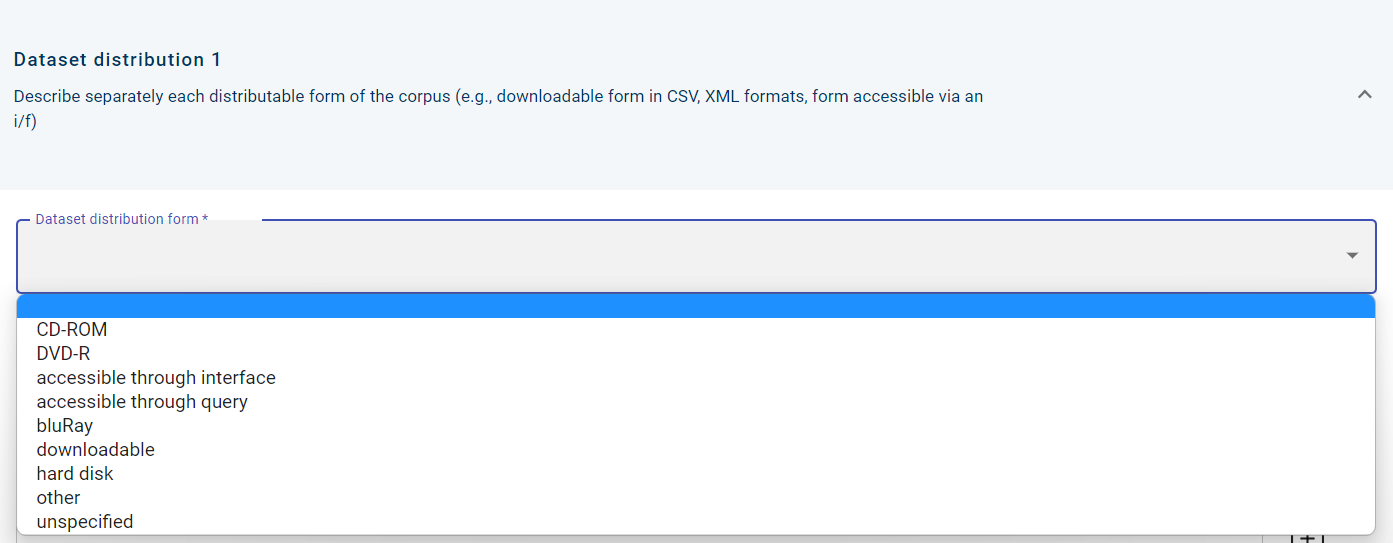
A resource might be available in more than one ways, in compact form (such as a CD-ROM, a DVD-R, a hard disk, etc.) or through an access point. If there are more than one distributions for a resource, each one must be independently described. A dropdown list offers a variety of forms to choose from.
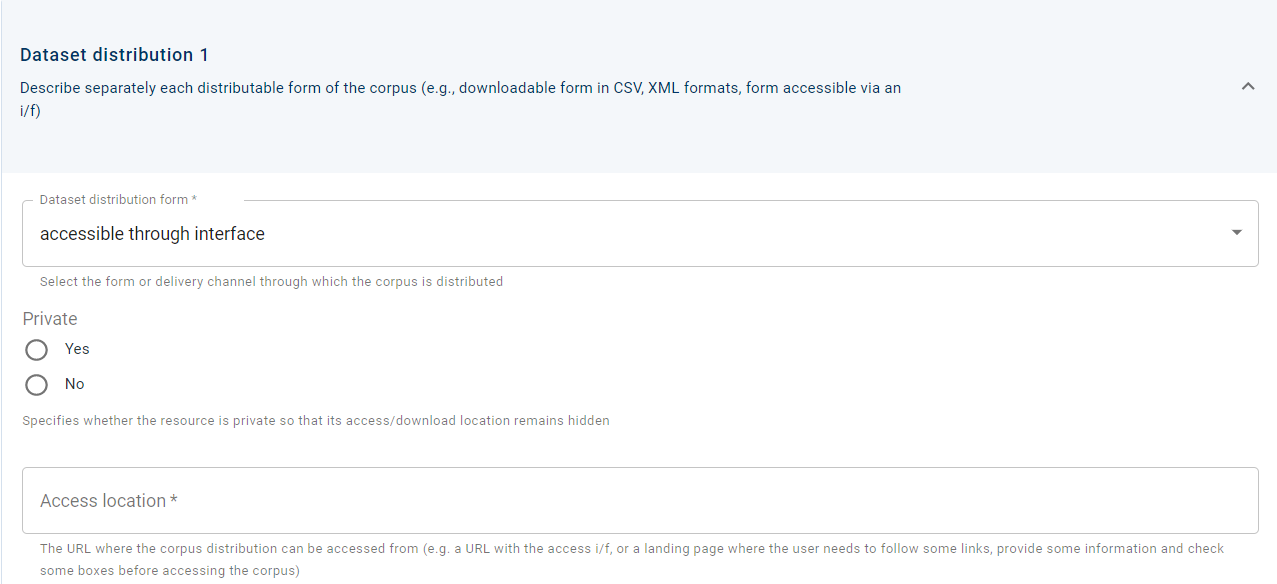
Once a value is selected, it generates its respective metadata elements, which must also be filled in. If, for example, a resource is accessible through interface, the access location metadata field is generated and you must fill in the URL via which the resource is accessible.
Attention
The CLARIN:EL infrastructure mainly hosts resources along with their data. Independently of whether the data have been uploaded upon the resoure creation or at a later stage, they must be associated with a distribution. The appropriate distribution has the value downloadable and although it generates the download location metadata field, this does not need to be filled in (since the data are downloaded from the CLARIN:EL infrastructure). What must be done is to create the association between the distribution and the data, as shown in the image below. Click on the zip file name to provide the association. Finally, for the process to be completed, you must save (or save as draft) the metadata record.
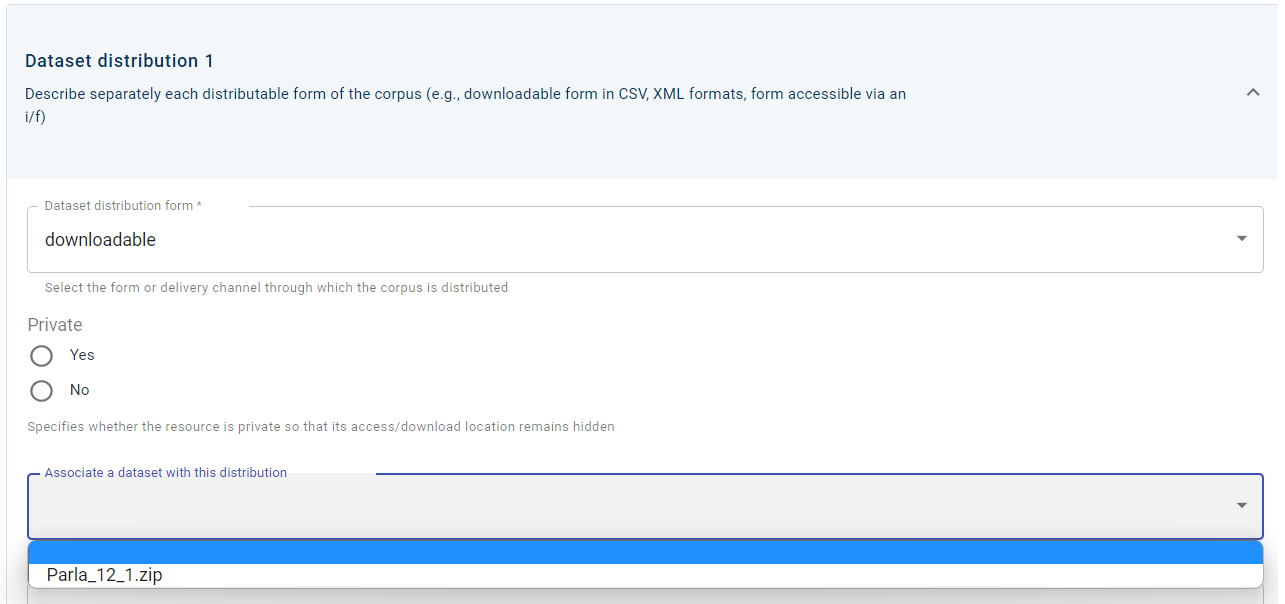
See how the
distributionelement is described in detail in XSD
7. licenceTerms related metadata¶
~The terms under which a resource is made available~
The licenceTerms related metadata consist of the name of the licence, the licence terms and the most frequently used conditions of use. The licence name is revealed once you start typing in the respective field. If it has already been used by another user, you will be presented with its full official name. If you click on it, the related metadata will be automatically filled in. For example, if the licence in question is the cc-by-nc-sa, then when you start typing, the matching options will be presented as shown in the image below.
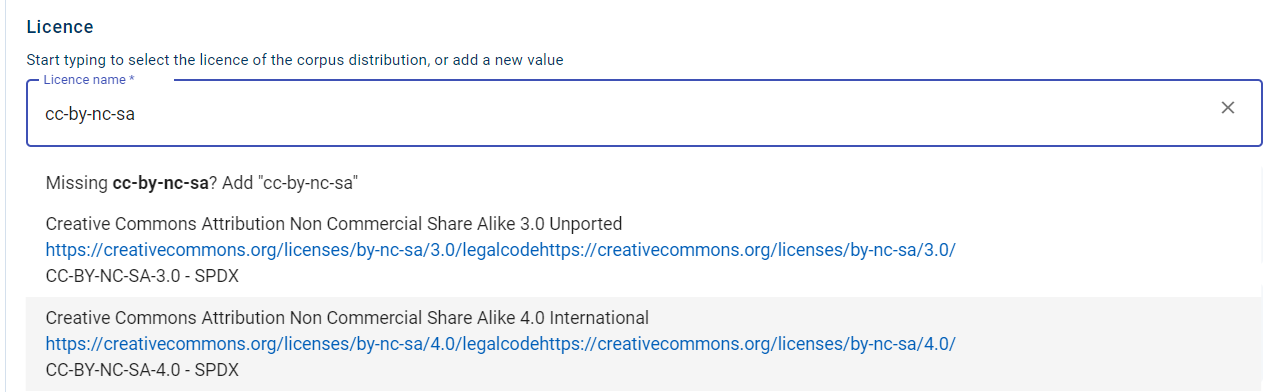
Click on the licence name you want to use from the suggested values. For this specific licence, the full name is Creative Commons Attribution Non Commercial Share Alike 4.0 International, the URL where the licence terms can be found is https://creativecommons.org/licences/by-nc-sa/4.0/legalcode, and the conditions of use are attribution, non commercial use, share-alike, all automatically provided in the respective metadata fields as shown in the image below.
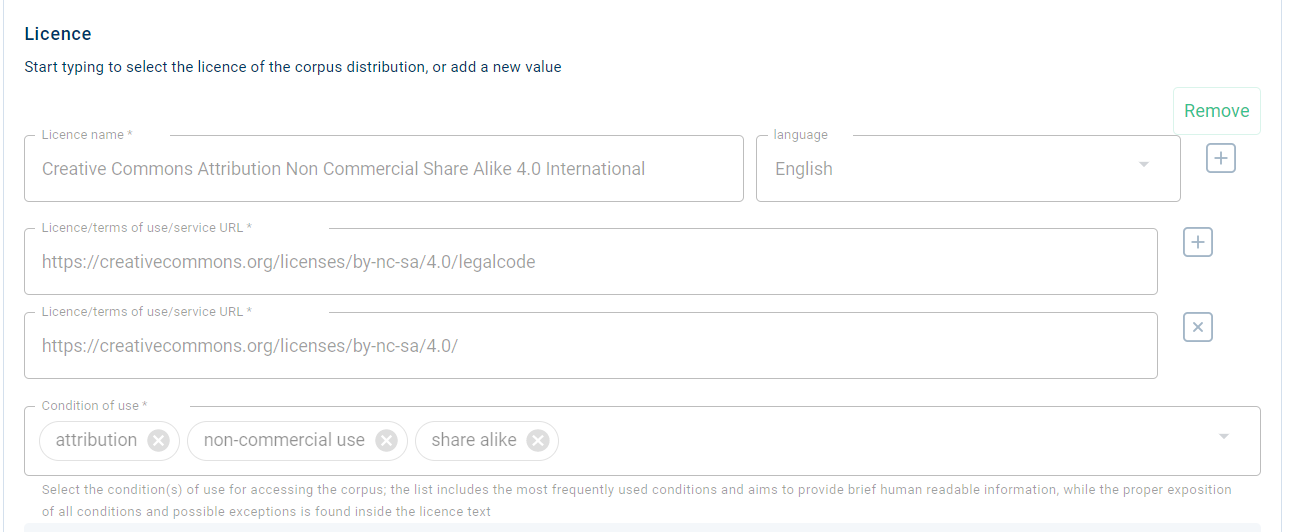
If the licence you wish to use has never been applied before, you will have to fill in manually the aforementioned metadata. See also the Recommended licensing scheme for Language Resources if you need help with which licence to choose for your resources.
See how the
licenceTermselement is described in detail in XSD
8. data¶
~The content files of a resource~
Not all resources have content files. A metadata description may or may not be accompanied by content files (see here for more information). See also the detailed guidelines on how to prepare data, the recommended formats and how to upload them.
9. personalData, sensitiveData & anonymized¶
~Information about whether the resource contains personal and/or sensitive data~
Attention
This metadata element is mandatory for corpora, lexical/conceptual resources and language descriptions.
You must specify whether the resource contains personal data (e.g. names) and/or sensitive data (e.g., medical/health-related, etc.) and thus requires special handling. If this is the case, new metadata fields are presented in which you can provide additional information on special requirements, if necessary.
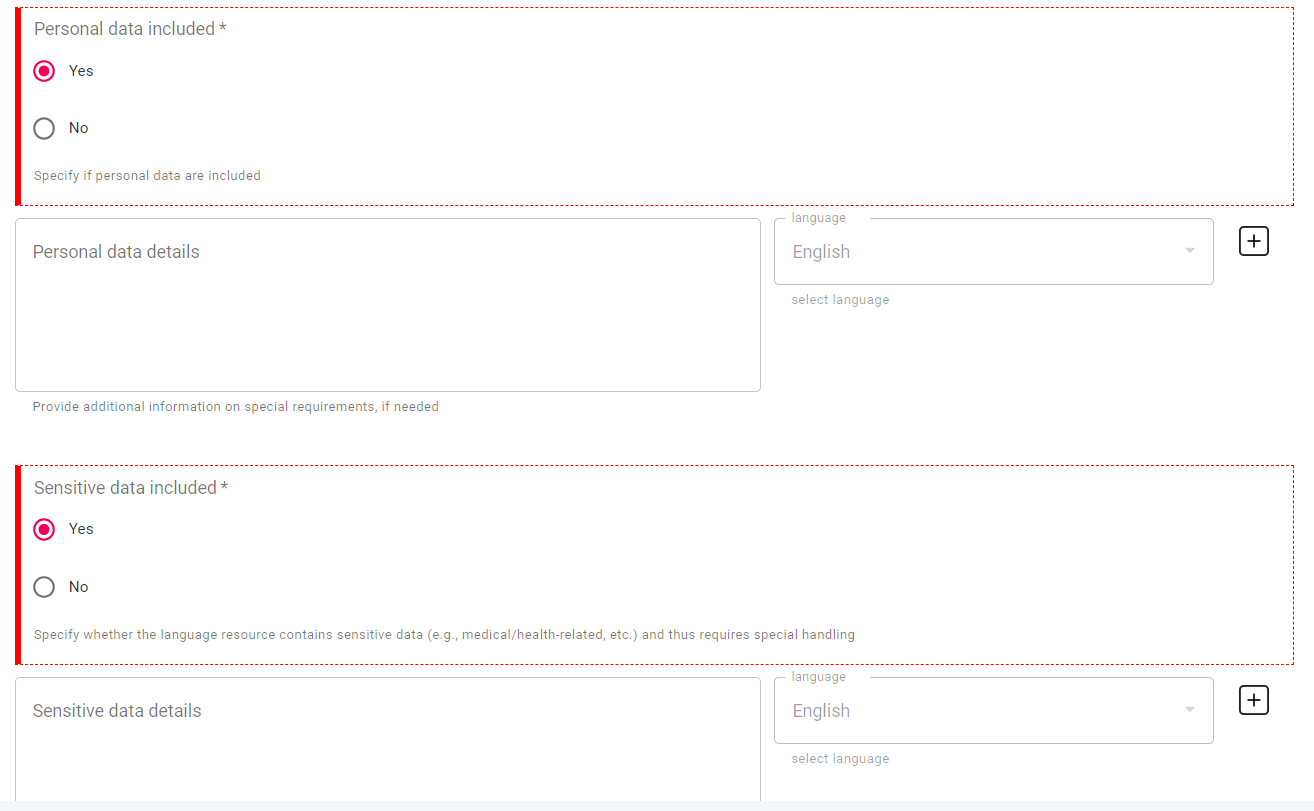
See how the
personalDataelement is described in detail in XSDSee how the
sensitiveDataelement is described in detail in XSD
The existence of personal and/or sensitive data generates 3 another metadata element, that of anonymization. Here you can provide all the information on the anonymization/pseudo-anonymization, the tool used, if specific code was written, any conventions adopted, etc.
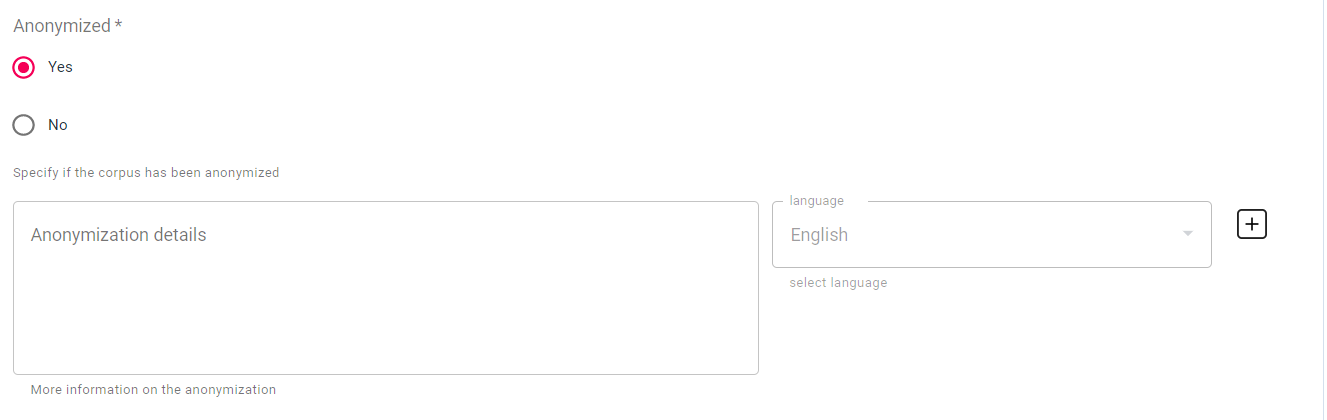
See how the
anomymizedelement is described in detail in XSD
10. Subclass related metadata¶
~The classes into which a language resource can be further categorized according to its type~
Attention
This metadata element is mandatory for corpora, lexical/conceptual resources and language descriptions.
10.1 corpusSubclass¶
For corpora the corpusSubclass categories are:
raw, for non-processed corpora,
annotated, for corpora that include both the raw corpus and the processed output,
annotations, for corpora that consist only of the processed output, and
unspecified, for corpora that cannot be described from one of the aforementioned categories.
The metadata element is found in the Corpus section (Technical tab) in the editor.
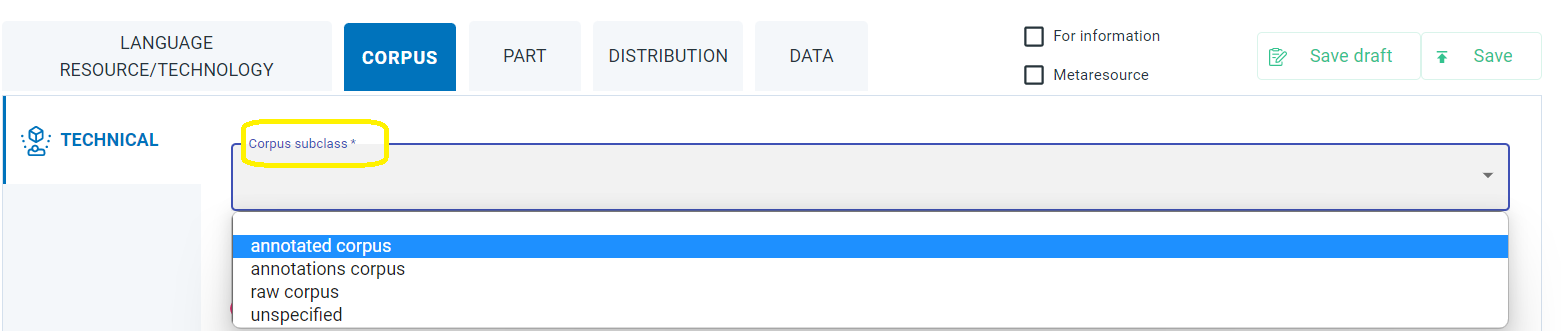
See how the
corpusSubclasselement is described in detail in XSD
10.2 lcrSubclass¶
A lexical/conceptual resource can be further categorized with the lcrSubclass element as:
annotation scheme: A set of elements and values designed to annotate data. It usually consists in a formal representation. It aims to represent a specific level of information, such as morphological features of words, syntactic dependency relations between phrases, discourse level information etc. It can consist of a flat structure of elements and values (e.g. part-of-speech tags) or it can be more complex with interrelated elements (e.g. specific morphological features to be used for each part-of-speech). 4
computational lexicon: a lexicon which is intended for computational purposes and thus contains words associated with information relevant for the specific purposes.
dictionary: a book or electronic resource that contains a list of words (usually in alphabetical order) and explains their meanings, or gives a word for them in another language and other information (e.g., spelling, pronunciation, etc.).
FrameNet: a lexical database based on annotating examples of how words are used in actual texts in accordance to the notion of ‘semantic frame’ (schematic representation of a situation involving various participants, props and other conceptual roles); originally built for English and extended to other languages according to the same design principles.
lexicon: (a list of) all the words used in a particular language or subject, or a dictionary.
Machine Readable Dictionary: a dictionary usually meant for humans in a form that a computer can process.
mapping of resources: a resource consisting of mapping values and/or rules between two resources.
morphological lexicon: a lexicon with morphological information associated with its entries.
ontology: a set of concepts and categories in a subject area or domain that shows their properties and the relations between them.
other: value used when none of the recommended values of an element is appropriate for an item.
tagset: a flat list of valid values (tags) designed to annotate data. It usually corresponds to a specific annotation type or set of annotation types. 5
terminological resource: a lexical resource that lists concepts pertaining to a specific domain.
thesaurus: a reference work that lists words grouped together according to similarity of meaning (containing synonyms and sometimes antonyms).
typesystem: a set of elements designed to annotate data. It typically contains only a list of annotation types, i.e. specific labels that are used for the annotation (e.g. part-of-speech, person, organization, etc.), and is usually inbuilt in the annotation software. 6
unspecified: value used for mandatory elements whose value is unknown or cannot be specified.
WordNet: a lexical database originally created for English and extended to other languages, which groups words into sets of synonyms called synsets, provides short definitions and usage examples, and records a number of relations among these synonym sets or their members.
wordlist: a written collection of all words derived from a particular source, or sharing some other characteristic.
The lcrSubclass categories are also alphabetically presented as a dropdown list in the editor LCR section (Technical tab).
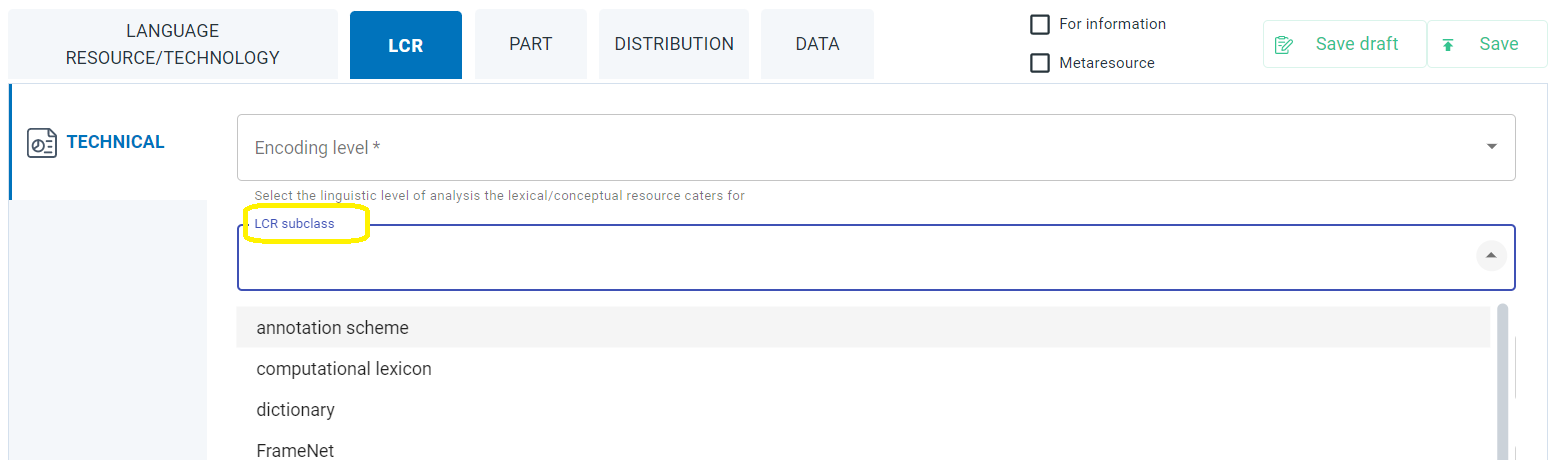
See how the
lcrSubclasselement is described in detail in XSD
10.3 LanguageDescriptionSubclass¶
A language description has three categories from which one can choose to describe in a more fined way a resource:
grammar: a set of rules governing what strings are valid or allowable in a language or text.
ML model: the ML model that must be used together with the tool/service to perform the desired task.
n-gram model: a language model consisting of n-grams, i.e., specific sequences of a number of words.
These categories are presented in the editor Language Description section (Technical tab) as a dropdown list.
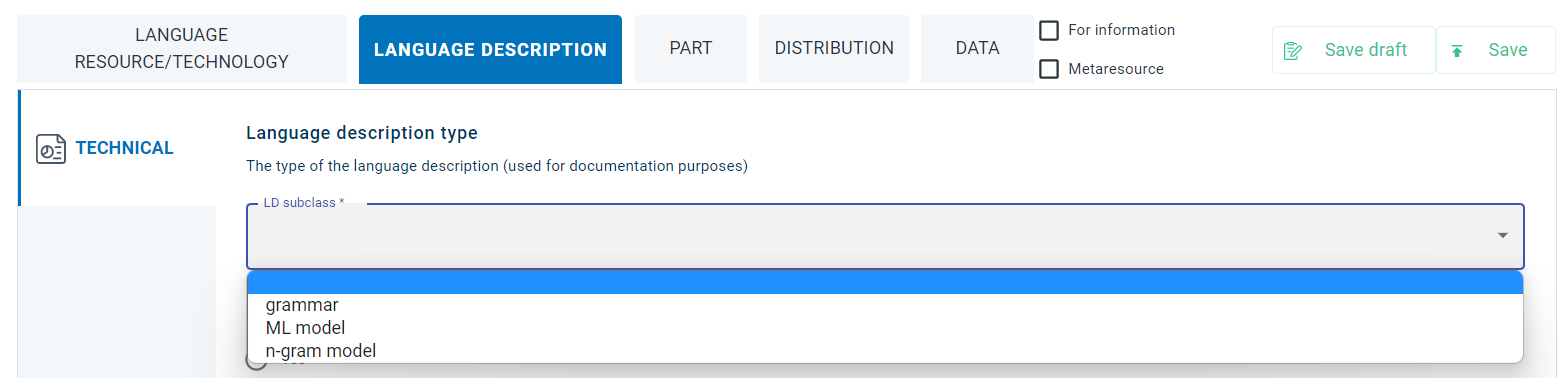
See how the
LanguageDescriptionSubclasselement is described in detail in XSD
11. encodingLevel¶
~Information on the contents of a resource as regards the linguistic level of analysis it caters for~
Attention
This metadata element is mandatory for lexical/conceptual resources and language descriptions.
The values for encoding refer to various linguistic levels of analysis. These levels are presented in alphabetical order below with their subject matters:
morphology: word formation (such as inflection, derivation and compounding);
other: value used when none of the recommended values of an element is appropriate for an item;
phonetics: speech sounds;
phonology: speech sounds that constitute the fundamental components of a language;
pragmatics: the relationship of sentences to the environment in which they occur;
semantics: the meaning of a word, phrase, etc.;
syntax: the structure of linguistic units (phrases, sentences);
unspecified: value used for mandatory elements whose value is unknown or cannot be specified.
The metadata field is found in the LRC section (Technical tab) for lexical/conceptual resources above the lcrSubclass as shown in the image below.

For language descriptions the metadata field is found in the Language Description section (Technical tab) below the chosen LanguageDescriptionSubclass.
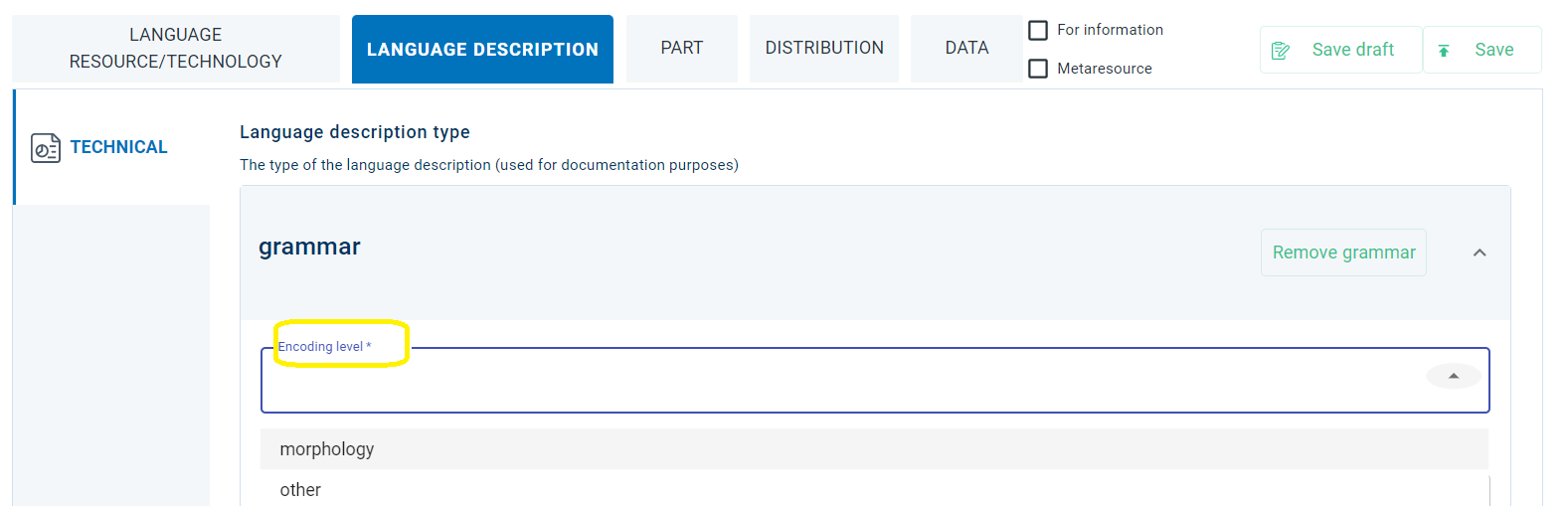
See how the
encodingLevelelement is described in detail in XSD
12. function¶
~The operation/function/task that a software object performs~
Attention
This metadata element is mandatory for tools/services only.
The dropdown list in the respective metadata field includes numerous values which cannot be presented all here. If you start typing, though, the list will be reduced only to the values matching your criteria. If the function of your tool/service matches one of the values suggested, click on it and it will be added. If the function of your tool/service does not match one of the values suggested, you must click on the prompt (missing…? add). Only then the value will be saved. If you omit this step, the function will not be appear when you revisit this editor section.
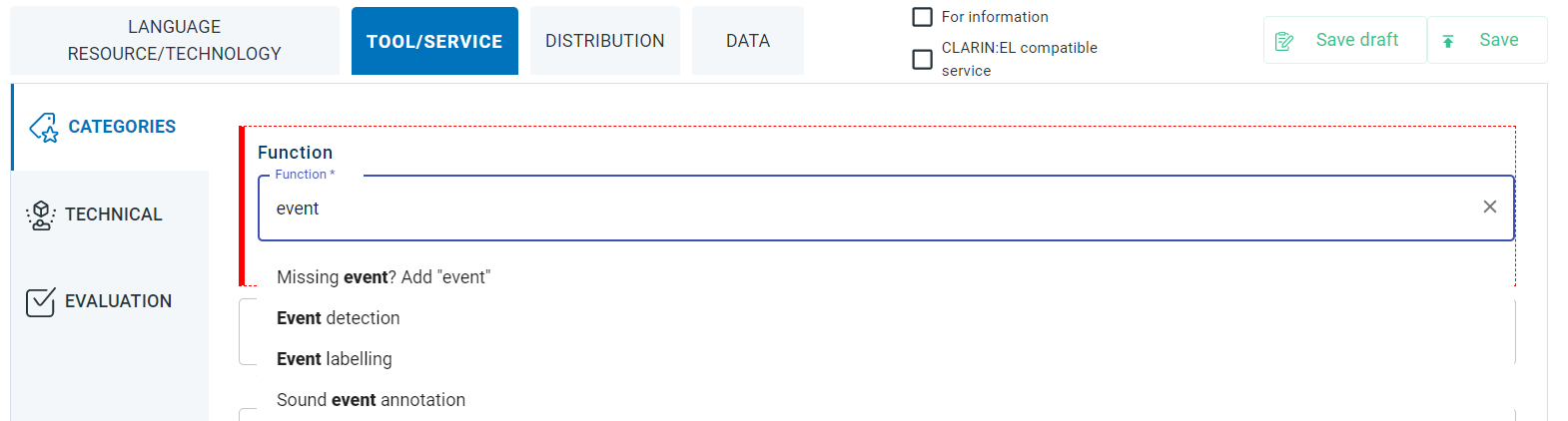
The metadata element is found in the editor Tool/Service section (Categories tab).
See how the
functionelement is described in detail in XSD
13. inputContentResource¶
~The requirements set by a tool/service for the (content) resource that it processes~
Attention
This metadata element is mandatory for tools/services only.
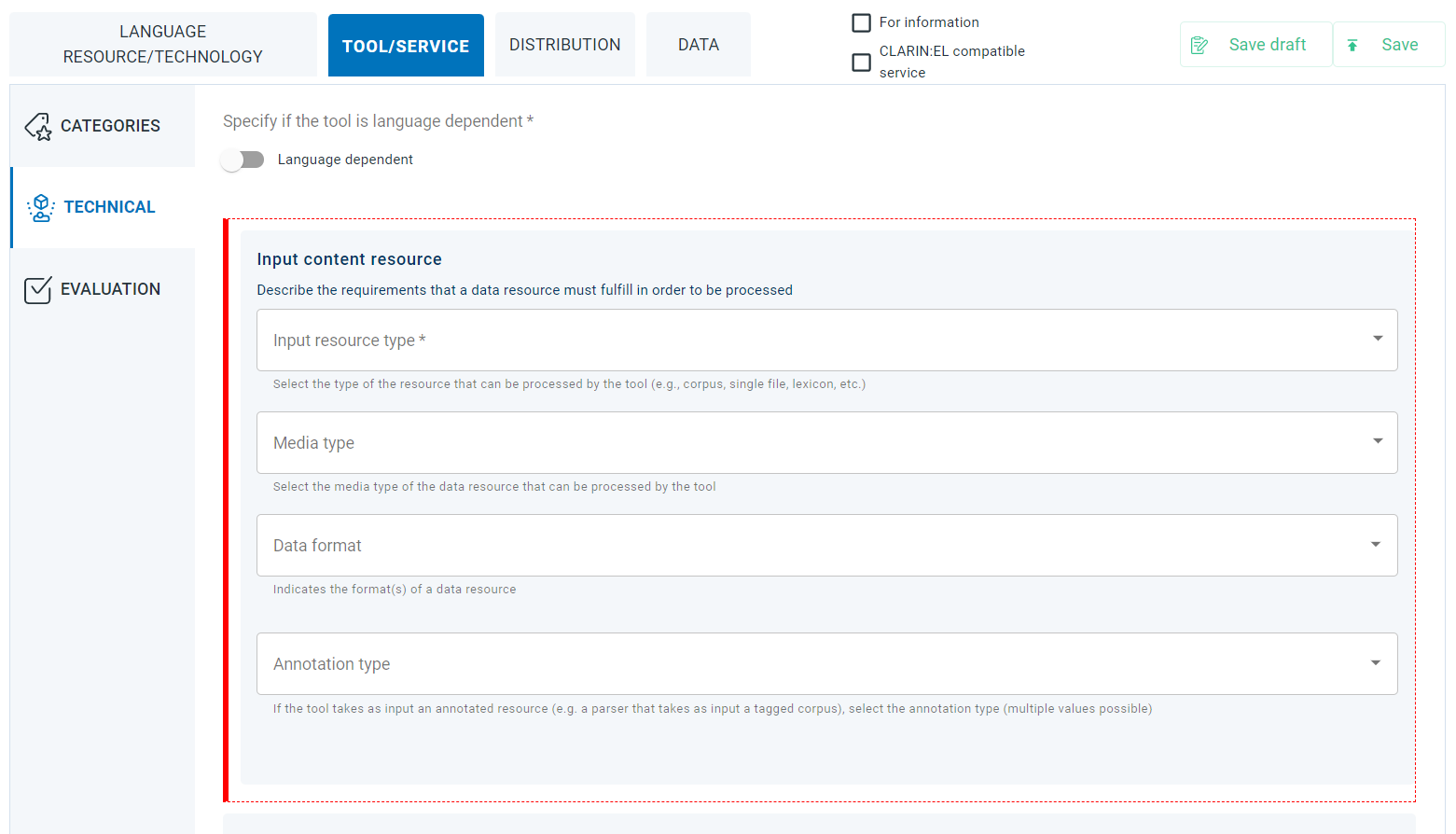
This is a complex metadata element which requires for four other metadata fields to be described: input resource type, media type, data format and annotation type. All these elements provide the necessary information on the resource that a tool/service processes.
For the resource used as input, a dropdown list provides the values shown in the following image. To choose one, click on the value.
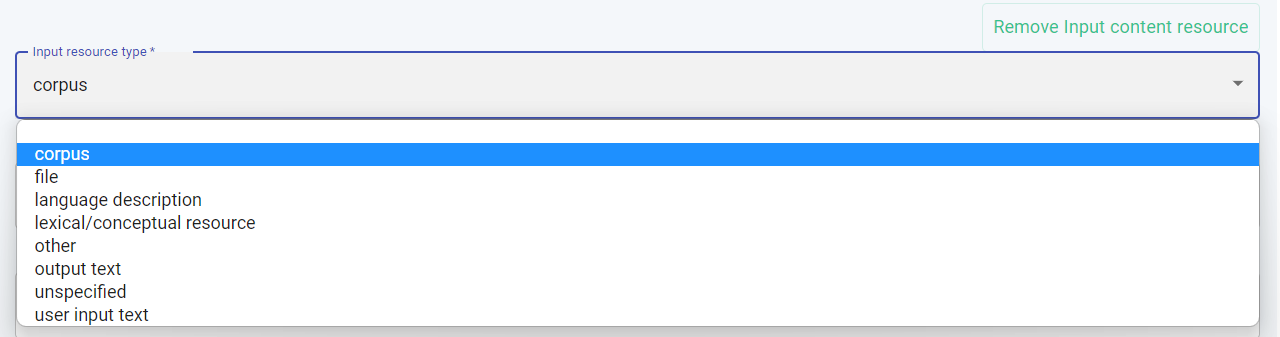
The next field to be filled in, requires information on the medium of the resource used as input. Again, click on a value to add it.

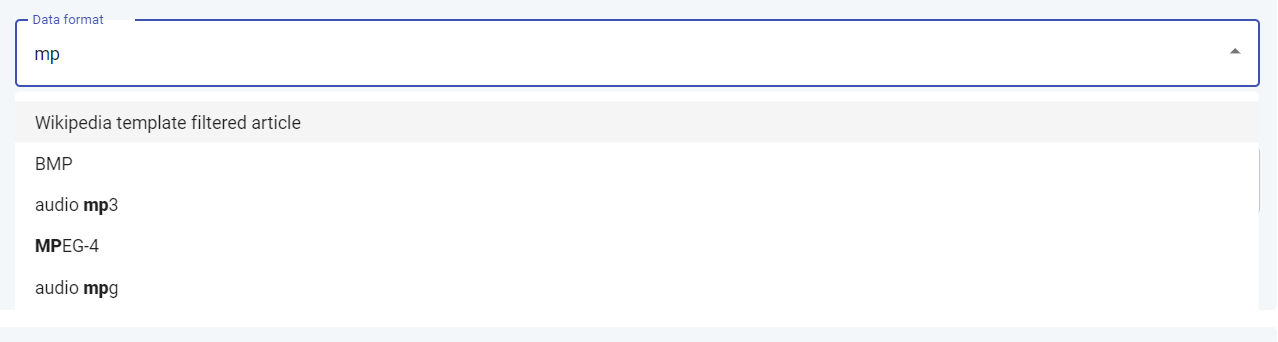
For the data format following, you must type in the box to reveal the values that match your criteria and eliminate all the others from the dropdown list. Once you have located the appropriate value, click on it.
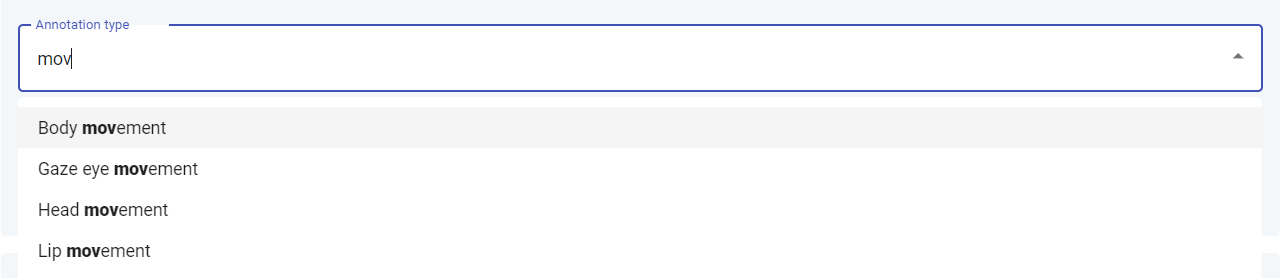
Finally, if the resource provided as input is annotated, you must define the annotation type. Once more, start typing in the box to reveal the possible corresponding values. Choose one by clicking on it.
The inputContentResource element is found in the editor Tool/Service section (Technical tab).

See how the
inputContentResourceelement is described in detail in XSD
- 1
Henceforth editor.
- 2
See the semantic versioning guidelines for specific instructions.
- 3
The
anonymizedelement belongs to the mandatory upon condition metadata, the necessity of which depends on the values of other elements provided by the user, such as the answer “yes” to the question about the personal and/or sensitive data existence in a resource.- 4
The difference between typesystem and annotation scheme is based on whether they are used by tools or defined by users: the annotation scheme contains custom types while the typesystem is mostly used for built-in types.
- 5
The difference between a typesystem and a tagset is that the typesystem will include only annotation types (e.g. an annotation type POS to represent part-of-speech annotations) while the tagset contains a list of the valid tag values (e.g. the Penn Treebank Tagset).
- 6
The difference between typesystem and annotation scheme is based on whether they are used by tools or defined by users: the annotation scheme contains custom types while the typesystem is mostly used for built-in types.