What can I find in the CLARIN:EL central inventory?¶
The CLARIN:EL infrastructure includes Language Resources and Technologies (LRTs), which can be further classified according to their content into:
corpora a.k.a datasets: collections of text documents, audio transcripts, audio and video recordings, etc. (for the corpora which can be used for processing see here),
lexical/conceptual resources, comprising computational lexica, gazetteers, ontologies, term lists, etc.
tools & services: any type of software used for LT processing (for the services integrated in the infrastructure see here), and
models & computational grammars, collectively referred to as language descriptions.
The following image depicts the taxonomy of resources in relation with other entities, such as the actor -i.e. the creator, contributor or annotator- who can be a person, a group of people, or an organization.
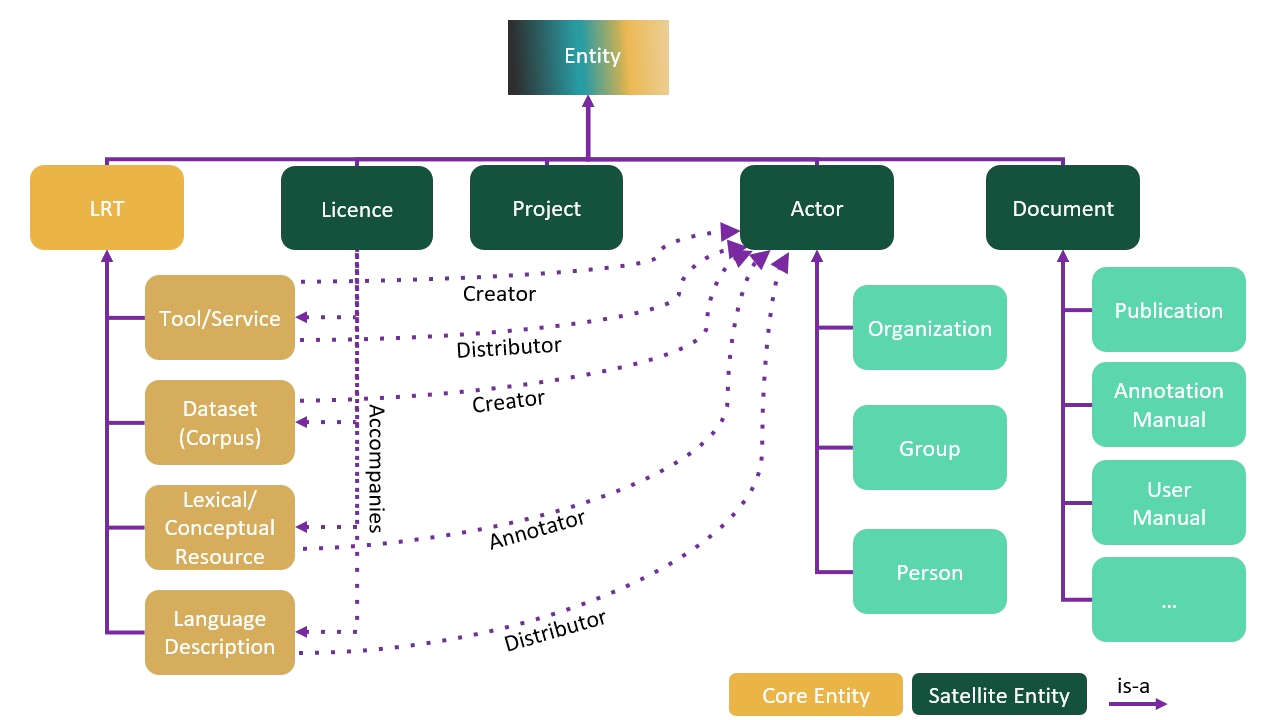
Typically a resource consists of a description (the metadata record) and content files (e.g. the dataset for a corpus, the software for a tool etc.). A description is a sine qua non condition for a resource to be in the central inventory. However, a description may or may not be accompanied by content files. Therefore, the following combinations exist:
Resource descriptions along with content files,
1.1 available through CLARIN:EL, or
1.2 available via an external link directing to another website or via an interface needed to access the resource.
Resource descriptions without content files, which are
2.1 for information purposes only (the content files will be uploaded later), or
2.2 metaresources (there are no content files to be uploaded); these include bibliographies, conference proceedings, etc.
As concerns resources with content files, you can find out here the conditions under which they are accessible.
Tip
See here some important information on creating and sharing resources via the CLARIN:EL infrastructure.